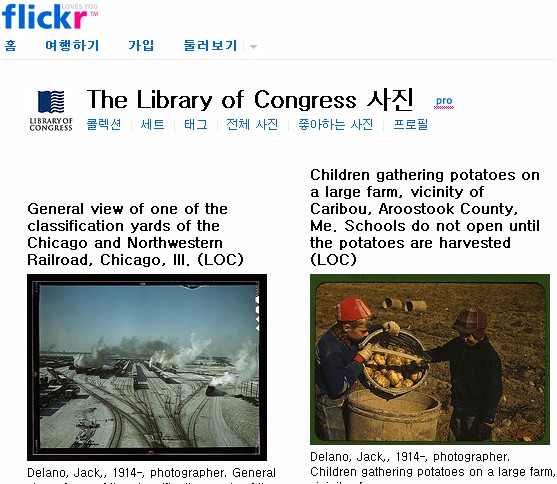
최근 미국 의회도서관은 플러커 사이트에 많은 양의 사진을 올려서 사람들이 메타데이터(태그)를 입력하도록 하는 파일럿 프로젝트를 시작했다. 도서관에서 하는 중요한 업무 중에 하나가 도서의 저자와 서명 등등의 메타데이터를 작성하는 목록이다. 요즘에는 종합목록이라는 것이 있어서 어느 기관에서 먼저 작성하면 그걸 자관에 맞게 수정해서 사용하는 경우나 상업용으로 작성된 걸 사용하는 경우가 많다. 하지만 사진같은 자료는 보는 사람에 따라 메타데이터의 내용이 달라질 뿐더라 양도 많아서 일일이 메타데이터를 작성하는 것은 정말 데이터 노가다와 다름없다.
그래서, 생각해낸 것이 집단지성, 집단노가다를 활용하는 웹2.0 방식이다. 도서관은 플러커에 저작권이 소멸된 사진을 올려둔다. 그러면, 엄청난 플러커의 이용자들이 사진을 보고 태그를 달기 시작한다. 그러면 자연히 사진들의 메타데이터가 작성되는 것이다. 결국 태그로 인해서 전에는 찾기 힘들었던 다양한 사진들이 검색을 통해서 발견될 수 있는 놀라운 결과를 만들어 낸다. 도서관과 이용자가 윈윈할 수 있는 멋진 아이디어다.

태안사태도 마찬가지다. 기계나 장비가 할 수 없는 부분을 인간들이 나서서 해결하고 있다. 인간이라서 할 수 있는 일이 있다는 것이 아직까지는 다행인지 불행인지 모르겠다. 하지만 웹2.0의 참여, 공유, 개방을 통한 협업이 비록 노가다일지라도 사회적으로 문화적으로 가치를 만들어내고 있는 건 사실이다.
'도서관' 카테고리의 다른 글
| DBPIA 논문 정보 - '사서커뮤니티'를 통해 본 대학도서관의 과제 (0) | 2008.01.25 |
|---|---|
| 인수위의 무소불위에 불타는 도서관 (0) | 2008.01.24 |
| 사서의 탈도서관화 (2) | 2008.01.12 |
| 도서관에 사는 기쁨 (0) | 2007.11.30 |
| 도서관2.0 글 모음 (0) | 2007.11.22 |